

002. Parler Analysis-Part II: What They Talk About When They Talk Online
002. Parler Analysis-Part II: What They Talk About When They Talk Online

The Story Continues
In our last post, we took an exploratory look at the “free speech” social media, Parler. Our analysis bore witness to the fact that Parler is an information hub for sources of extreme ideologies and mixed factuality. Now that we know that Parler carries out the patina of bogusness and extremism, a natural question to follow up is to investigate what is being discussed in these posts—what their talking points were when they referred to sources with different biases and factuality, and what were mentioned in these sources.
To analyze this topic in a feasible and scalable manner, a naïve approach was adopted. Basically, we wanted to build classification models for factuality and bias using the texts—the opposite of what we have done in the previous post, where we treated factuality and bias as the dependent variables. This time, words or words collocations were generated as the features for the models. By doing so, we postulated that important features helping with the classification can be somehow understood as important texts that are most relevant to specific bias and factuality.
In a nutshell, the focus of this blog is to understand what was discussed, mentioned, and posted when Parler users used external sources with different sources and biases. Specifically:
What are the most important text features to predict posts with different biases, especially extreme-right bias?
What are the most important text features to predict posts with different factuality, especially mixed to low factuality?
Before we jump on the boat, there are several presumptions to adopt. First of all, we are assuming that the texts in these posts are considered as online discussions or discourses. Oftentimes, when people repost news to social media platforms, they just use the headlines of the news article (Khanlian, 2017). Although the news headline can describe the context of the discussion, some might argue that those are not the original opinions or thoughts from the users. Therefore, it’s debatable to say whether these texts qualify for the representativeness of understanding online discussions or discourses. However, to distinguish the nuances of users’ opinions and the news’s original headlines is difficult without an existing research dataset, so in this post, we are assuming that most texts are associated with user’s own ideas, and even if the texts in the posts were merely a copy-paste of the news headline, it would still inform us about the user’s thoughts and thus is useful for this analysis.
Secondly, we are also assuming texts can be used to build classification models for the factuality and bias, indicating their predictive power suffices to make tenable conclusions. In this post, we are not trying to propose new models or techniques, nor we are trying to emulate the state-of-art for document classification. I’m mostly interested in the text inferences; therefore, as long as the model gives out acceptable accuracy and has no blatant errors, model fine-tuning for an improvement for several points of accuracy is peripheral to this specific post.
Lastly, the text features should be theoretically independent, but in reality, that’s not possible because some words naturally appear together. That being said, they were still treated as independent variables for the model.
A Kaleidoscope of Conservative Talking Points
The text data were cleaned in a standardized natural language processing fashion, including lowercasing, and the removal of digits, punctuations, diacritics, stop words, and whitespaces. The Bag-of-words model was utilized to each of the cleaned documents and uni-, bi-, and tri-grams were generated as the features. The dataset for factuality classification contains 23,714 documents and bias 21,826.
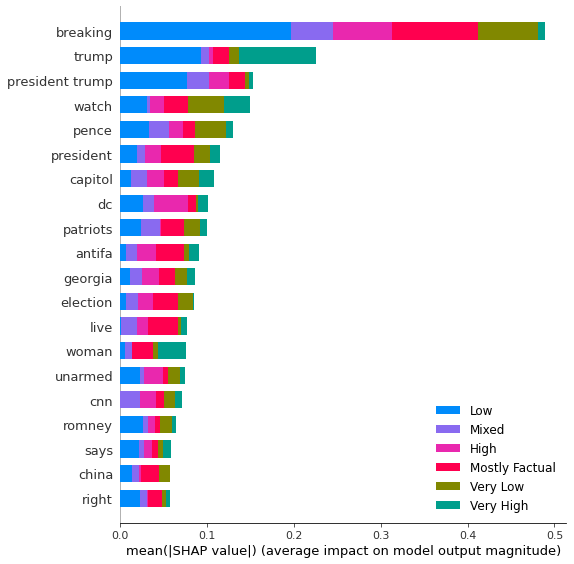
Simple logistic regression models were built upon the cleaned dataset. The factuality model reached acceptable accuracy (M=0.66, STD=0.007). The model was further analyzed using SHAP (SHapley Additive exPlanations) values (Lundberg & Lee, 2017), with an 80:20 hold-out validation set. Figure 1 displays the summary of the top 20 most influential features based on the mean SHAP values. These keywords can be roughly grouped into several clusters. The first would be the common filler words in news headlines, for example, “breaking” topped the chart, which is clearly serving as an attention grabber. Other words in this category would be “live”, “watch”, and “says”. The second group is the politicians—and Trump is the biggest star on Parler with two top-level entries. We also see other prominent GOP politicians like Pence and Romney made into the top 20. The third group revolvs the Capitol riots, as we have “DC”, “capitol” and possibly “patriots” ranking in the middle. Also, the discussion of the 2020 election was presented as we saw “election” in the chart. “China” and “Georgia” were the only two geographical entities besides DC. “CNN” was the only media mention. And, of course, “ANTIFA” was discussed a lot, unsurprisingly. When looking at the SHAP value for each class, the general trend is Trump is associated with a lot of low/mixed factuality sources. Very low factuality sources tend to have “watch”, “Pence”, and terms related to the Capitol riots.
To better understand the association between different factuality and the n-grams, we sorted the feature coefficient for each class, and first visualize the largest coefficients, as shown in Figure 2. These features positively contributed to the classification of factuality. These terms gave us clues to loosely comb the current affairs being discussed on Parler.
News about COVID is more likely to come from sources with high factuality, so as MEGA2020. Most factual sources are mostly reports of executive orders or memorandum. The memorandum here referred to the memo monitoring ANTIFA, which was signed by Tump and published on Jan. 5th. The executive order was mostly about Trump’s executive order to prevent ANTIFA members from entering the U.S. In sources with very high factuality, the articles have “Korean” in the post. The event is about armed Iranian troops boarded a South Korean tanker. Sources with mixed, and lower factuality have several political figures mentioned, namely Trump, AOC, and Flynn. Overall, as factuality moved to the lower end of the spectrum, the more likely it was about a specific person.
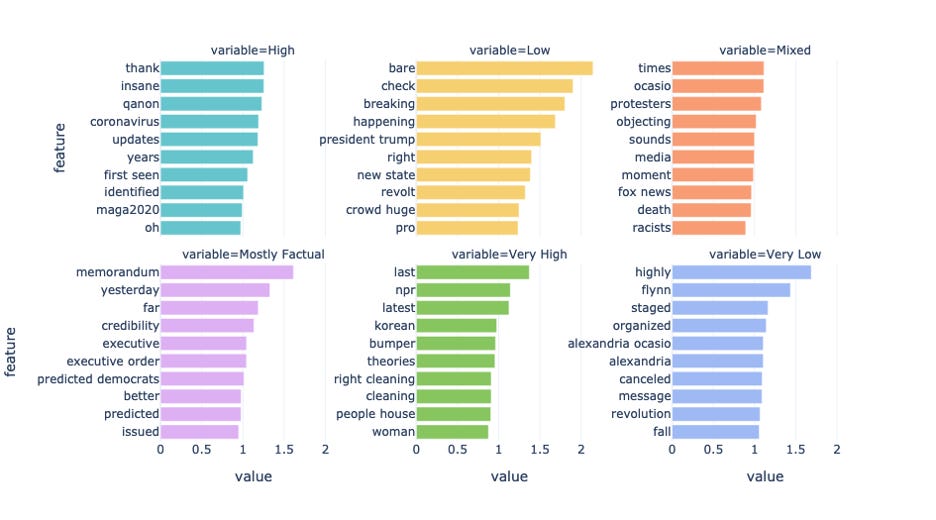
Figure 3 shows the smallest features for the factuality model— the features with negative coefficient—the terms that were least likely to indicate a certain class of factuality. Generally speaking, these should somehow mirror the distribution of words in Figure 2, as our factuality labels are ordinal and in a diverging scale. That is to say, a word positively contributes to the factuality of high will probably indicate negatively contributing the opposite of high, which shall be the factuality of low. We did observe this for some words, for example, “QAnon” positively contributed to the factuality of high and now negatively contribute to low. However, a new set of words that didn’t appear in Figure 2 ended up in Figure 3, notably “DC”, “Fox”, “GA”, and “Joe Biden”. It’s implying that a source with these words is not likely to be in a high-factuality source, but they do not necessarily only appear in low-factuality sources. In fact, they appear in other sources except for high-factuality sources. That’s why they didn’t become a distinguishing feature of low factuality, and thus not enlisted for the chart above.

The same analysis was conducted for the biases as shown in Figure 4. As a whole, the most important features for bias were similar to that of the model for factuality. New words that appeared for this model include “COVID”, “Republican”, “BLM”, etc.

Features with the largest coefficients were also plotted in Figure 5. For this model, a lot of derogatory words appeared in the chart. For example, “idiots” and “bastard” for left-biased sources, “libtard” for the least biased group, and “idiot” in the extreme-left group. Most names, like Trump, Pompeo, and AOC, are in the group for right-biased sources. The right-center group focused on discussing a group of people rather than a specific person since “antifa” and “democrats” were ranked within the top 10. The Left-center group came up to be more of subjective statements or descriptions of the policy, as we again saw “memorandum” and “executive order” here.

Figure 6 shows the smallest coefficients for the bias model. Extreme-right sources seemed to avoid words like “lockdowns”, “capitol”, “fact”, and “proof”. The least-bias sources were negatively associated with “traitor” as well as “patriots”, which makes sense for nuetral sources to eschew using strong and objective words. Left-biased sources were negatively associated with not only “republicans” but also specifically Trump and Pence. Additionally, Biden, the US, China were not in their realm. Left-center sources had Pelosi, DC, and Fox as the keywords. Right-biased sources contained two entries for Pennsylvania. It’s referring to the news that Pennsylvania GOP leaders asking for an Electoral College certification delay.

After the examination of these two models, we observed that some keywords became the most influential features for both the factulaity model and the bias model. It might be more informative to combine the results of two models to see the cooccurrence of bias and factuality. Figure 7 shows the positive coefficients for bias and factuality models. There is a lot of clickbait coming from sources with low factuality and extreme-right bias. This also affirms previous research that analyzed the features of fake news (Mourão & Robertson, 2019). Another group of words is from the left-center and mostly factual sources, denoting the execution of policies.
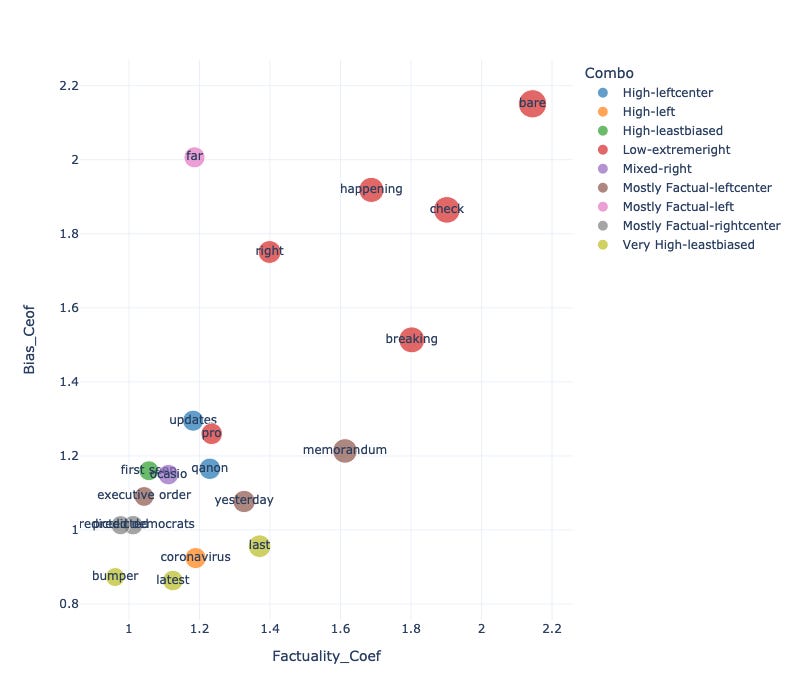
Figure 8 shows the features with negative coefficients for both models. The most obvious group had the factuality as most factual and bias as least biased. Words falling into this group stayed off using “patriots”, “traitors”, and “votes”.

Figure 10 shows the last combination of bias and factuality. Two groups stood out: extreme-right bias but not very-low factuality and extreme-right bias but not high factuality. The words in the clusters are fillers at best and aren’t informative about the topics.

Summing It Up
In this post, we briefly examined the relationship between the keywords and the factuality/bias of the source. In summary, we found out that:
Sources with different factuality and bias did have their preferences in word usage and topics. This was supported by the predictive power of the corpus.
The most prominent events that were also most influential features include the presidential elections, the Capitol riots, and the memorandum targeting ANTIFA.
Several politicians turned to be important text features, including Trump, Pence, Pompeo, and Flynn. AOC is the most discussed/reposted figure from the left-leaning side.
Georgia and Pennsylvania were the states that appeared as the most important features for the model—their appearances were closely associated with current affairs. China is the only country that held significant influence on the bias of the reposted news.
Sources that have higher factuality tended to focus on COVID, policies (memorandum and executive policies) and were least likely to associate with patriots, traitors, and Joe Biden. On the other hand, low factuality sources that were carried to Parler heavily associate with specific politicians like Trump, Flynn, and AOC.
Extreme-right sources on Parler accentuated the discussion on election “fraud”. Right-wing sources covered the discussion of AOC, Trump, Pompeo, and CCP. Left-biased sources were mostly used to report the new policy and policy execution.
Extreme-right and low factuality sources extensively used sensational words and clickbait.
References
Khanlian, G. (2017). Good News or Bad News: Analyzing News on Social Media Platforms.
Lundberg, S., & Lee, S.-I. (2017). A Unified Approach to Interpreting Model Predictions. ArXiv:1705.07874 [Cs, Stat]. http://arxiv.org/abs/1705.07874
Mourão, R. R., & Robertson, C. T. (2019). Fake News as Discursive Integration: An Analysis of Sites That Publish False, Misleading, Hyperpartisan and Sensational Information. Journalism Studies, 20(14), 2077–2095. https://doi.org/10.1080/1461670X.2019.1566871